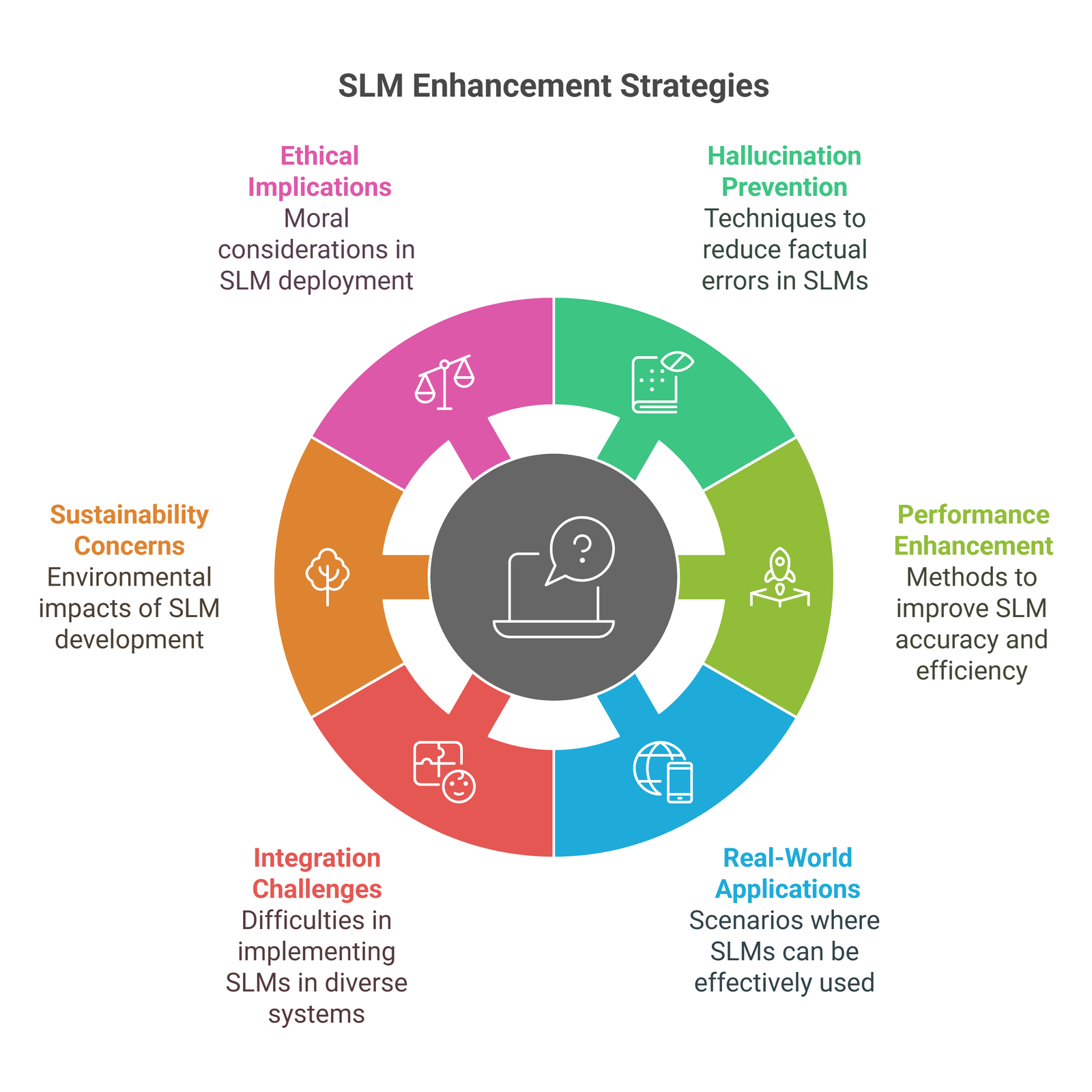
Small Language Models (SLMs) offer a computationally efficient alternative to Large Language Models (LLMs), enabling natural language processing (NLP) capabilities in resource-constrained and/or private environments such as personal computers, mobile devices, embedded systems, and real-time applications. However, SLMs face significant challenges related to factual hallucination, limited generalization, and degraded task performance due to their reduced parameter capacity. This review provides a comparative analysis of current methods to mitigate hallucination and enhance performance in SLMs. We consider hallucination prevention techniques into five primary strategies: retrieval-augmented generation (RAG), instruction tuning and prompt engineering, fact-checking and verification layers, calibration mechanisms, and fine-tuning with human feedback. In parallel, we explore performance enhancement methods including quantization, pruning, parameter-efficient tuning, knowledge distillation, mixture-of-experts architectures, and domain-adaptive training. A comparative evaluation highlights trade-offs between accuracy, compute efficiency, and deployment feasibility. We identify best-fit combinations of techniques for diverse real-world scenarios—ranging from mobile applications to safety-critical systems—and discuss integration challenges, sustainability concerns, and ethical implications. This work is aimed to introduce and compare methods for developing robust and efficient SLMs capable of reliable deployment across varied NLP contexts.
Senel FA, Ozmen HB. A comparative review of hallucination mitigation and performance improvement techniques in Small Language Models, Res. Des. 2025; 2(1): 45-65. DOI: http://dx.doi.org/10.17515/rede2025-004en0523rs